DeepSeek's Three Innovations: Young Geniuses, Team Power, and Philosophical Thinking
DeepSeek’s innovation transcends traditional models. Combining youthful genius with collaborative synergy and philosophical thinking, it’s redefining AI development. What if this approach sparks a new wave of groundbreaking organizations and ideas? Dive deeper to discover how.

As someone deeply involved in this field (a North American PhD, formerly with Meta AI, now an AI entrepreneur), I was profoundly impressed by DeepSeek. I spent most of the Lunar New Year poring over every paper they published, alternating between slapping my thigh and marveling, "How are they this incredible?!" (laughs).
Upon reflecting more calmly, I realized that DeepSeek is redefining the concept of innovation for both Chinese and American perspectives. There must be an underlying structural capability, a new paradigm, either intentionally or unintentionally crafted by Liang Wenfeng and his team. This, perhaps, is the greatest insight DeepSeek offers to the world:
The Three Pillars of DeepSeek’s Innovation:
- Scaling up individual genius
- A Huawei-style legionary advance
- Original, philosophy-driven ideas
The Triumph of the Young Geniuses
What’s the first impression when reading DeepSeek’s papers (Math, V2, V3, R1, Janus)? It feels like an endless shower of groundbreaking research, pelting you with originality from all directions.
Training large models is a highly complex, software-hardware-integrated endeavor. Yet DeepSeek has practically redesigned most of the critical components: MLA, GRPO, DeepSeek MoE, Dual Pipe, FP8 mixed precision, R1-Zero, MTP, and more. The sheer scope and density of these innovations are nothing short of astounding.
From an academic perspective, many of these innovations, even when taken individually, are of a caliber worthy of Best Paper awards at top-tier conferences. This marks the first of DeepSeek’s three pillars, and to explore it further, let’s start with a diagram—the brilliant young minds behind DeepSeek.
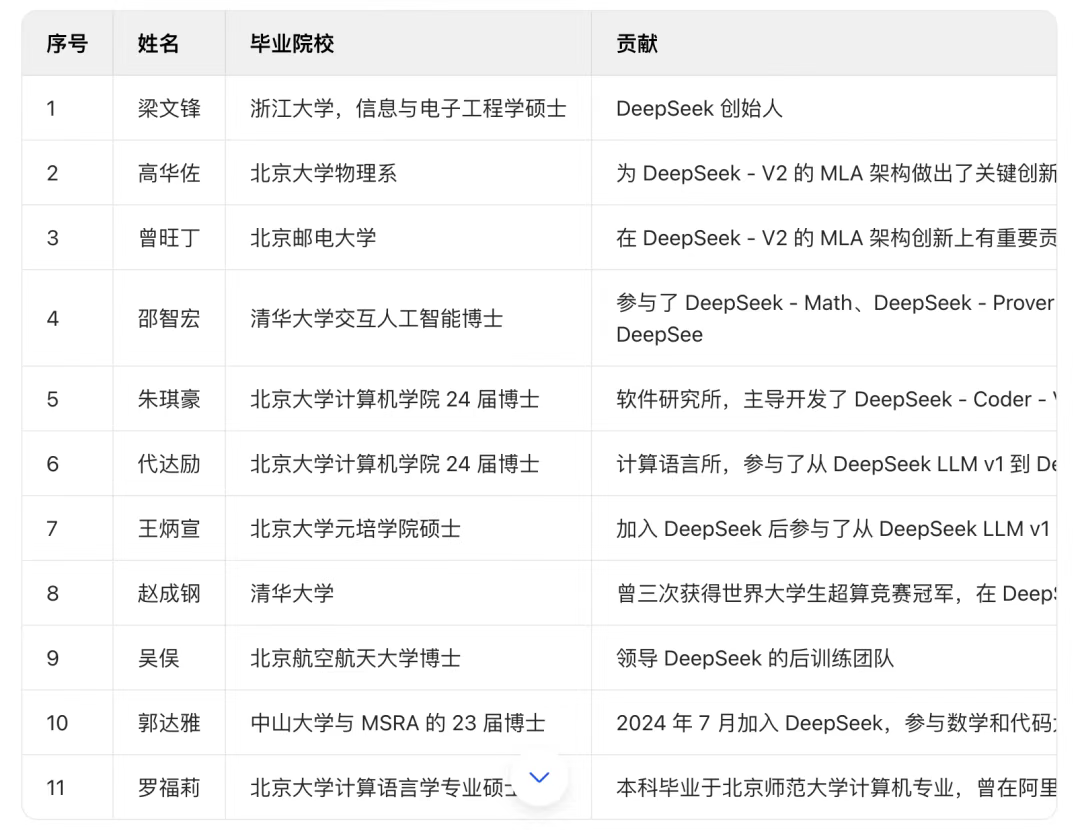
Many people have seen this chart, but upon further research, I discovered there are many others not included in it. Many of them have backgrounds in international competitions (such as Wu Zuofan, Ren Zhizhou, Zhou Yuyang, and Luo Yuxiang). Quite a few are still interns or just starting their PhD journeys (like DS-Math authors Zhi Hong Shao, Peiyi Wang, and Zihan Wang). Yes, it’s this group of young individuals who created the series of technologies mentioned earlier.
The phenomenon of "young genius" innovation has a well-known parallel in the United States. Alec Radford, the original proposer of GPT; Jason Wei, who introduced the Chain-of-Thought (CoT) reasoning method; and Bill Peebles, a key contributor to Sora, were all either early in their careers or lacked formal doctoral training.
I call them "young geniuses" because they possess not only extraordinary learning abilities but, more importantly, a lack of the burden of entrenched knowledge.
Young Genius-Style Innovation in DeepSeek
If we were to define "young genius-style innovation," it would be the ability to find optimal solutions within given constraints. Let’s look at three core algorithmic modules from DeepSeek as examples:
- MLA: Traditional attention mechanisms consume too much memory. The solution? Redesign the attention module using low-rank compression to optimize the efficiency of the KV cache.
- DeepSeek MoE: Traditional Mixture of Experts (MoE) models have coarse-grained experts and high activation parameters. The solution? Enhance MoE by introducing shared experts and fine-grained experts, significantly improving the effectiveness of expert learning.
- GRPO: Traditional Proximal Policy Optimization (PPO) requires training two models, which is inefficient. The solution? Remove the value model and introduce Group-Relative baselines, greatly improving training efficiency.
Putting aside the technical jargon, here’s a more intuitive explanation: A highly skilled engineer encountering a problem will try different technical approaches and pick the best one. A young genius, on the other hand, will say, “None of these are good enough—why not create something entirely new?” Then, they proceed to develop the best solution in the industry.
This pattern appears repeatedly in DeepSeek’s research papers, and behind each instance stands a young genius.
Scaling Up Young Genius Innovation
Believing in individual creativity, especially from young people, is deeply ingrained in Silicon Valley culture. Perhaps my own experience serves as an example: after graduating and joining Meta, I proposed building a completely new content understanding engine just six months in. A month later, a virtual team of about ten people was formed to bring it to life.
I imagine Liang Wenfeng drew significant inspiration from OpenAI’s approach. In several interviews, including one with Dark Current, he expressed similar views. He emphasized that this kind of young genius-driven innovation happens daily in Silicon Valley. However, this doesn’t diminish the significance of DeepSeek, which not only proves that China can foster a Silicon Valley-style culture of innovation but also shows that this model can be scaled further.
After all, we have the largest pool of young geniuses in the world. (laughs)
Now imagine this culture spreading to more innovative companies, becoming the mainstream. What kind of flourishing scene would that create?
This is the first gateway to innovation.
Huawei-Style Legionary Advancement
If DeepSeek were merely replicating Silicon Valley’s “young genius” model, why has it caused so much concern for the likes of OpenAI—the very pioneers of this approach? The answer lies in the second key factor.
When you dive deeply into DeepSeek’s papers, particularly V3, a new realization gradually emerges: this is a sophisticated and intricate system, spanning from foundational hardware to cutting-edge algorithms. It’s built with elegant top-level design, where every layer is intricately connected, and it advances through disruptive and sweeping progress.
This represents the second gateway to innovation: legionary collaborative innovation. This approach is exactly where China excels, and why I draw parallels with Huawei.
Silicon Valley guru Peter Thiel once provided a profound insight into this type of innovation. He argued that true monopolistic innovation requires the construction of a complex, vertically integrated system, where innovations at many different levels must occur simultaneously and come together in a highly coordinated manner. According to Thiel, Elon Musk’s success fundamentally stems from his relentless pursuit of such integrated systems. Interestingly, Musk is often seen as the closest parallel to Chinese enterprises in some respects (not just in his intensity, laughs).
How Does DeepSeek Drive Collaborative Innovation?
In the first gateway, we focused on the extreme optimizations of three algorithms under a magnifying glass. However, such point-specific optimizations often introduce challenges beyond the scope of algorithms alone.
Now, let’s shift perspectives and analyze DeepSeek’s innovation structure from a broader viewpoint. The first layer of understanding is their model iteration timeline (leaving aside many side projects):
- June 2023: DeepSeek was founded.
- February 2024: Released DeepSeek-Math, introducing GRPO.
- May 2024: Launched V2, introducing MLA and DeepSeek-MoE.
- November 2024: Launched V3, featuring MTP and a comprehensive software-hardware co-optimization strategy.
- January 2025: Released R1, introducing R1-Zero.
Impressive, right? From the debut of DeepSeek-Math to the release of R1, it took less than 12 months. But speed isn’t even the main point here.
The real breakthrough lies in their vertical integration: they essentially rebuilt an entire system, from infrastructure and foundational hardware optimization to algorithmic innovation. What’s more, these elements are highly coordinated and optimized, showcasing a seamless logic of progress—“building roads through mountains and bridges over rivers.” Let me try to break it down:
- Infrastructure: Built their own cluster (Firefly). To enable more efficient parallel training, they developed the HAI LLM training framework in-house.
- Memory Efficiency: Addressed the high memory overhead of traditional Attention by redesigning it with MLA (low-rank compression), reducing KV cache usage by over 90%.
- MoE Improvements: Tackled the lack of shared and fine-grained experts in traditional MoE models by designing DeepSeek MoE, solving issues of precision and shared knowledge.
- Load Balancing: Solved training imbalances for fine-grained experts by developing their own routing algorithm, ensuring even training distribution.
- Pipeline Parallelism: Designed the DualPipe algorithm to eliminate bandwidth mismatches between communication and computation during pipeline parallelism.
- GPU Optimization: Bypassed CUDA limitations by writing directly in PTX (low-level language) to precisely control GPU SM and Warp numbers for communication handling.
- Bandwidth Utilization: Addressed NVLink and IB bandwidth disparities by designing MoE routing to use four nodes per expert and optimize intra-node communication.
- Tensor Parallelism: Minimized communication overhead in tensor parallelism by using MLA’s recomputation methods to free up memory, effectively skipping the TP process.
- FP8 Mixed Precision: Developed fine-grained FP8 mixed precision to drastically reduce computation and communication while maintaining training effectiveness.
- MTP Introduction: Incorporated MTP to increase training density and efficiency in each iteration.
- R1 Distillation: Enhanced V3 inference capabilities by distilling them into R1.
- Self-Play Limitations: Overcame limitations of small models in self-play inference learning by distilling large-model reasoning into smaller models.
- ... and more innovations
Finally, the climax: At the end of their V3 paper, they dedicated an entire section to proposals for hardware manufacturers on designing next-generation chips, including detailed ideas on communication and quantization operators.
And that’s when it dawned on me: DeepSeek envisions the creation of AGI as a vast blueprint, one without boundaries. Algorithms? Communication? Data? Hardware? All fall within their scope, all tackled in a coordinated manner. Frankly, I believe that if given enough resources and time, they’d build their own hardware, even their own power grid.
This is what true innovators look like. As Steve Jobs once said: “People who are serious about software should make their own hardware.”
The Chinese Element Behind It All
Unlike the "young genius" model, this coordinated, system-driven approach is something Silicon Valley culture tends to overlook—Elon Musk being a notable exception.
When I returned to China in 2019, I was surprised to find that ByteDance and Kuaishou had more advanced recommendation systems than Meta. This led me to learn more about Huawei. Over time, I witnessed how organizations like Huawei, emblematic of the Chinese organizational model, unleashed immense power on the global stage—in fields like electric vehicles, content distribution, smart hardware, and even e-commerce.
But today, we’re talking about AGI—a domain that could redefine the trajectory of human civilization. DeepSeek’s meteoric rise in this field has once again shattered global expectations.
This is the second gateway to innovation.
In DeepSeek, we see what happens when the first gateway of innovation (the "young genius" model) merges with the second gateway (systematic, collaborative innovation). Boom! The resulting impact is nothing short of extraordinary.
Original (Philosophical) Thought
Is it possible to dig even deeper? Could there be an even more fundamental element of innovation? What forms the foundation of a groundbreaking system like o1 or R1?
The answer lies in an original, entirely new system architecture. And where does this original structure come from?
To answer that, I’d like to quote a favorite passage from Ilya Sutskever:
"I like thinking about very fundamental questions... You can almost think of them as philosophical questions. For example, what is learning? What is experience? What is thought? ... I see technology as a kind of natural force, but it seems that we can design algorithms to do useful things while also answering these (philosophical) questions. It’s like applied philosophy."
Exactly. The third gateway to innovation is the creation of something philosophical in nature—an original, almost philosophical form of thought.
Zooming out, we can identify three pivotal sources of AI innovation over the past decade:
- Google’s Transformer (2017): A structure to understand the world and its intrinsic relationships.
- DeepMind’s AlphaZero (2017): Compressing the complexity of the world into intuition through constant prediction.
- OpenAI’s GPT (2018): Building deep thinking based on intuition to further abstract the world.
But these aren’t merely three models—they embody three philosophical ideas about the nature of "learning":
- Understanding structure (Transformer).
- Predicting and compressing complexity into intuition (GPT).
- Using intuition to construct deeper abstraction and thought (Zero).
The OpenAI o1 or DeepSeek R1 we see today are results of these three philosophical ideas combined. From these ideas, foundational system architectures were built. Then, through the first and second gateways of innovation, these structures were polished, recombined, and brought to life as world-changing products.
Why is the creation of philosophical ideas so profound? Because their purpose is not merely to find an excellent solution but to ask the most fundamental questions.
The Final Piece of the Puzzle
I don’t know if Liang Wenfeng is China’s Ilya Sutskever, but I firmly believe that an organization crossing the three gates of innovation needs a visionary leader. Isn’t that precisely what OpenAI lacks today?
No one can predict the future. But perhaps one day, in a new paper from DeepSeek, we might see an entirely new idea on the level of Transformer or AlphaZero.
Let’s be bolder: What if, inspired by DeepSeek, we see the rise of many new, innovative organizations of the next era? These organizations would cross the first and second gates of innovation in their respective fields and produce a generation of disruptive thinkers, along with original, philosophical ideas.
Even bolder: What if these ideas and innovations were shared transparently and openly with the world? Would you be more willing to participate in such a world?
This is what DeepSeek will truly leave behind in history.
Note: The sources for this article primarily come from DeepSeek’s V2, V3, R1, and Math papers, as well as industry insights on DeepSeek, rather than strict factual evidence. Any errors, please forgive the DeepSeek team.